Stop The Lead Scoring Madness
I recently came across a lead scoring article on the Mattermark blog that reminded me of a post I’ve been wanting to write for a while: the way nearly everyone is doing lead scoring is totally wrong. In the modern era of data-driven marketing where marketers boast about being able to connect every penny of marketing spend to revenue, we are using nothing more than gut instinct and anecodotal feedback to figure out the best leads to pass to sales. The main culprit for this data-driven nightmare is the way lead scoring is implemented in marketing automation systems like Marketo and Pardot. For example, here’s how lead scoring currently works in Pardot: at the system level, you can assign points to specific actions like email opens, page views, form submissions etc.

You can also add points as a completion action to things like form submissions to weigh specific types of actions and content more heavily than others; like maybe an analyst report or a specific webinar.
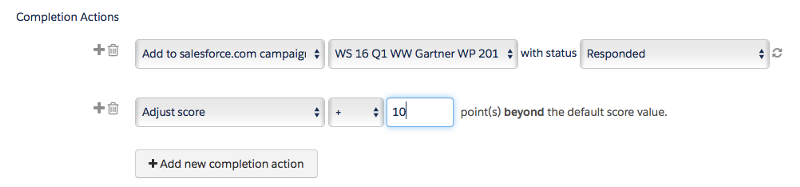
The idea of course is that now we can pass the highest scored leads to sales, and that there is a correlation between the lead score and likelihood to buy.
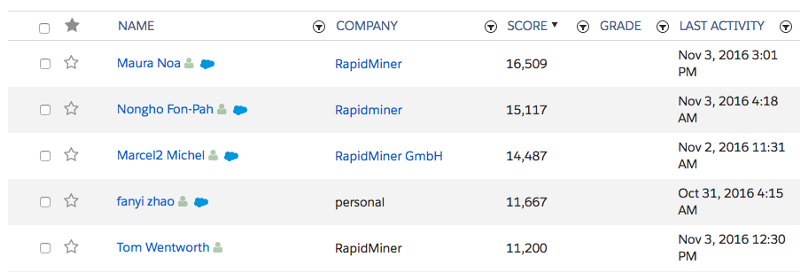
But as Mike Volpe points out the way we assign “points” makes absolutely no sense, yet somehow it has become accepted as the gospel of modern lead management best practices. [embed]https://twitter.com/mvolpe/status/786317672237535233[/embed] It turns out that accumulating points is actually a terrible way of predicting an outcome, leading to marketing passing horrible leads to sales; like the serial webinar attenders (you know, those people that come to EVERY SINGLE WEBINAR you run) and habitual email openers— instead of the people most likely to actually buy your product. It’s likely that much of the benefit of manual lead scoring comes from the placebo effect of telling sales that you are only passing them the best leads. So in turn they work them more exhausitively, and you’ll get better results than the unscored leads of the past that sales would mostly ignore. But that doesn’t mean they are better quality leads. They could actually be worse and you’d never know it. Don’t believe me? Here’s an A|B experiment you should run immediately: Take 10–25% of your lower scored leads using your current lead scoring model and start passing them to sales. The leads should appear like the rest of the higher scored leads(MQLs) you are currently passing to sales, and don’t tell anyone so there is no bias on how the leads are worked. Make sure you can identify leads in the experiment group against the control group. Run the test for as long as it takes for your test to hit statistical significance, which will be based on how many of your leads convert into whatever metric you are using to gauge the health of leads e.g. SAL, SQL, etc. In a few weeks after your sales team finishes following up on the batch of leads, compare the two groups using whatever conversion metric you are using. Now did the higher scored leads convert better than the lower scored leads? When I ran this experiment at my last company they didn’t — and the lower scored leads converted at a slightly better rate than the higher scored leads. Oops.
Building a lead scoring model by assigning random points to actions and attributes of leads is just about as un-data driven as it gets.
The solution is to build a lead scoring model based on a proven mathemetical model that will really tell you the features — or attributes of a lead — that have a statistically significant corrleation with the outcome you are trying to predict e.g. people who buy your product. Unlike the randomness of assigning points to specific behaviors and attributes of a lead, a predictive model will give you a statistical measure of which features actually matter the most. There are predictive marketing products that will do this for you — like Infer, Mintigo, and Everstring. But they come with a hefty price and are overkill for many companies. You can get started for free using tools like RapidMiner Studio or even good old Microsoft Excel. The first problem you’ll need to tackle is getting access to clean data. Predictive lead scoring is mostly a “wide data” problem; you want as much data as possible about your users to uncover the specific features that have the most impact on closing deals. This means combining data from your CRM and marketing automation system, hopefully your product, and perhaps even external APIs. But chances are the data from your CRM and marketing automation system is clean enough to get started. Once you have the data, you’ll model it using a variety of machine learning techniques, and most likely you’ll start with some form of regression. I won’t attempt to explain the math behind regression here, but if you are interested here’s a good overview from RapidMiner founder Dr. Ingo Mierswa. Here are two resources for getting started with either Excel or RapidMiner Studio for free:
- This video from Ilya Mirman, the VP of Marketing at OnShape, shows you how to build a predictive lead scoring model in Excel using linear regression. Okay fine, Ilya is a Stanford-educated engineer and MIT MBA, but the approach he outlines is something even mere mortal Excel power users could figure out with a little bit of effort. If you can do a VLOOKUP, you can try this.
- With a bit more effort you could download RapidMiner Studio, which will help you both prepare your data and build your predictive model. RapidMiner Studio provides far more options for modeling than Excel, and will help you get a more accurate predictive model. The current lead scoring model we’re using at RapidMiner was built by my colleague Thomas Ott, and here’s a webinar where he walks through how we built the model complete with a sample of our data and the model we use today.
Regardless of which tool you use, you’ll get a result that looks something like this — a weighted view of the lead attributes that actually result in more deals.
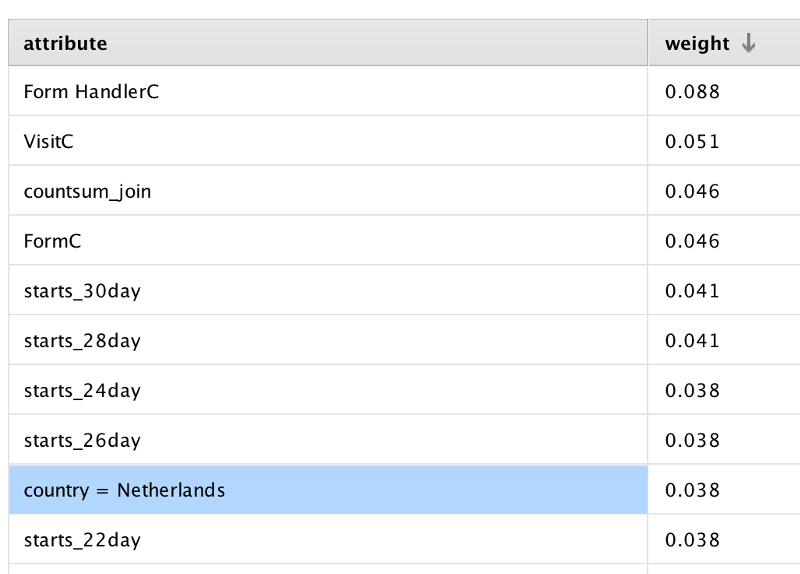
For example, in our RapidMiner lead scoring model. the number of product starts was the most important factor in predicting a purchase, and leads from Netherlands were more likely to close than any other country. We used RapidMiner Server to automate adding our predictive lead score to Salesforce, but even a simple Excel output of your weighted attributes is enough for you to make those marketing automation point assignments using mathetically-sound principals instead of educated guesses. And that’s a huge step in the right direction, and you didn’t even have to spend a bunch of money on a predictive lead scoring product to make it happen. Lastly, I highly recommend everyone read Myk Pono’s opus on How To Design Lead Nurturing, Lead Scoring, and Drip Email Campaigns. Myk goes into this and many more topics in great depth. Whew, feels good to get that post off my chest :)